
Publisher: Supplier of LED Display Time: 2022-06-28 20:30 Views: 2260
Introduction to Audio and Video Technology
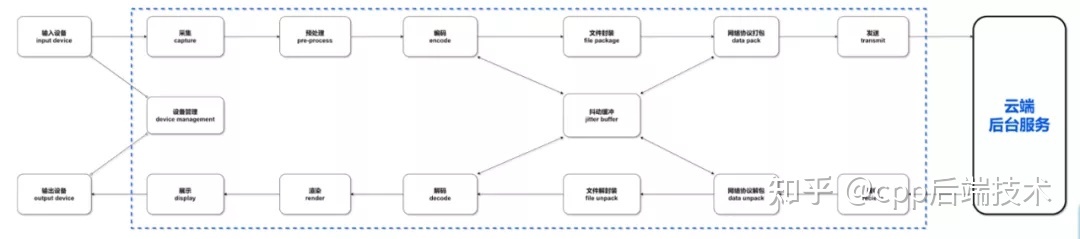
What is audio and video technology? Audio and video technology is actually a general term for audio technology and video technology. In terms of technical processing, audio and video are actually processed separately.
And it should be noted that audio and video are inseparable from hardware equipment from the beginning of data collection to the final display, so in the future development process, we must be mentally prepared to deal with hardware.
The main processing process of audio and video:
1. Collection. For example, obtain basic audio and video data from the client's camera, microphone and local original files;
2. Preprocessing. At this stage, the audio and video are actually trimmed. After all, the raw data collected is not necessarily the effect that you want to present at the end, so beauty, cropping, AI recognition processing, sound A3 processing, etc. may be performed here;
3. Coding. The original files that have been preprocessed or have not been processed are generally relatively large and are not suitable for transmission. At this time, operations such as compression and transcoding are required to reduce file submissions, and then transmit them. The tool for encoding is called Encoder, the algorithm for compressing data is called encoding format;
4. Decode. After the compressed data is transmitted, it needs to be decoded into the same data as the original file before it can be used. The tool used for decoding is the decoder, but usually the encoder and the decoder are one piece, collectively referred to as the codec codec;
5. Rendering and presentation. After receiving the original data file, it can be rendered and displayed through hardware or software, such as hardware such as monitors, speakers, etc., and software such as SurfaceView;
6. File encapsulation/decapsulation. In fact, from the acquisition, audio and video are processed separately, but when transmitting, we need the same set of audio files to be in one piece, so a file encapsulation is required. The container for storing audio and video is called the packaging container, and the file type is called the packaging format;
7. Network protocol packaging. When audio and video files are transmitted in the network, there is generally a specific protocol, that is, the streaming media protocol.
The network protocol will package the audio and video data files into a protocol package and send it out through the network protocol port. After the receiver receives the network package, it needs to unpack the protocol package through the network protocol to obtain the audio and video data file.
The main parameter of audio and video is the format
Video parameters:
1. Resolution: the size of the video area (pixels);
2. Frame rate: the number of frames per second, fps;
3. Bit rate: The amount of data per second in bps (b = bit).
Audio parameters:
1. Sampling rate: the number of audio points collected per second in Hz;
2. Number of channels: the number of channels to collect sound at the same time, common mono and stereo channels;
3. Bit width: Also called sampling bit width, it refers to the number of bits in which a single sound sample point is stored, usually 16 bits.
Raw data format:
Video: YUV, RGB;
Audio: PCM
Encoding format:
Video: H.264 (also called AVG);
Audio: AAC, Opus
Package format:
Video: MP4, FLV, TS;
Audio: not encapsulated
video frame vs audio frame
A video frame is equivalent to a picture, and the combination of multiple pictures can be switched at an extremely fast speed to form a video. Although it is just a picture, there are many types of video frames, which I will introduce later.
Type of video frame
At present, video frames are mainly divided into the following categories:
1. An I frame is a key frame, which records a complete image and can be directly decoded and displayed. A group of frames between two I frames is called a GOP (group of picture);
2. P frame, no picture is recorded, the difference between this frame and the previous frame is recorded, P frame cannot be directly decoded, and the pre-order reference frame needs to be decoded first;
3. The B frame records the difference between this frame and the previous I/P frame and the next I/P frame;
4. The rest are SI and SP frames, which are used for switching code streams and are generally not common.
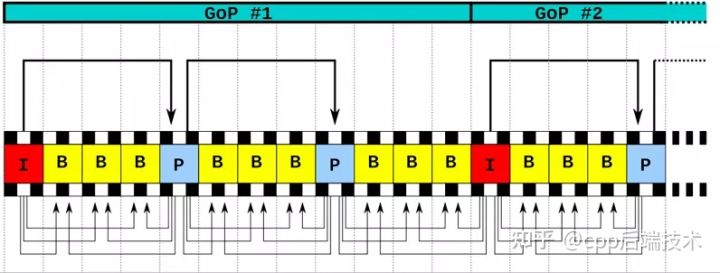
P frame and B frame are mainly used for compressing video. The principle can be understood. I frame stores the original image, so the amount of data stored will be relatively large. If the proportion of I frame appears more, then the whole video more data.
At this time, the appearance of P frame and B frame can significantly reduce the amount of data. The P frame will only compare the difference between the previous P frame or I frame and store it. The amount of data is much smaller than that of the I frame, and the compression ratio is about 20. In addition, the B frame will compare the difference between the previous I/P frame, the next I/P frame and the current frame, and store them. Because the two frames are compared, the amount of data stored in the B frame will be smaller. The ratio can reach 50.
In the live broadcast, there is basically no B frame, because the B frame needs to be analyzed and compared with the two frames before and after. The time for a large number of analysis increases a lot of delay, but it cannot be all I frames. The amount of data in I frames is too large. If all I frames are used, the efficiency will be very poor. Therefore, live broadcasts generally use a combination of I frames and P frames.
[Article benefits] C/C++ Linux server architects and audio and video learning materials are required to add group 812855908 (the materials include C/C++, Linux, golang technology, kernel, Nginx, ZeroMQ, MySQL, Redis, fastdfs, MongoDB, ZK, streaming media , audio and video, CDN, P2P, K8S, Docker, TCP/IP, coroutine, DPDK, ffmpeg, interview questions of large factories, etc.)
Video clarity
The quality of a video is related to the bit rate, resolution, compression ratio, frame rate, and GOP length of the video. Only when they achieve the best balance can they present the best picture quality.
For example, in our impression, the higher the resolution, the clearer the picture quality. This is not a problem. After all, the higher the resolution, the more pixels are allocated to the picture, and the better the details are depicted. However, it should be noted that the higher the resolution, the greater the amount of data. The larger the amount of data, the higher the required bit rate. Only a high bit rate can ensure the normal output of our video data. , if the bit rate is low, it will cause the video to freeze, which is the "video cache" we often see.
However, many video software now also do some operations to reduce the stuttering effect caused by the bit rate, such as adjusting the compression ratio. The higher the compression ratio, the smaller the amount of data and the reduced bit rate required. Of course, the sacrifice is The resolution of the original video. At present, many software will automatically adjust the compression ratio for you.
So what role does frame rate play in this? Everyone who plays games knows that the higher the frame rate, the higher the smoothness of the game. The frame rate is the refresh rate of the video, which is the number of frames refreshed in one second. For example, if the frame rate is 30fps, you can understand that 30 A drawing of continuous action is read in front of your eyes for a second.
Generally speaking: around 30fps, you can feel that the action is already coherent; 60fps experience can already achieve a sense of realism; if it exceeds 75fps, it is generally impossible to notice the improvement of fluency.
The frame rate is divided into the monitor frame rate and the video frame rate, which is to be careful not to confuse. So here we can discuss what happens if the video frame rate is different from the monitor frame rate.
In fact, the video frame rate is controlled by the graphics card drawing speed. If your graphics card drawing speed is 30fps, and the display frame rate is 60fps, the display refresh speed is faster than the graphics card drawing speed. At this time, the display only refreshes the latest frames. , there will be no difference in the viewing experience.
But if the frame rate of the monitor is 30fps, and the graphics card is 60fps, then the problem comes, because the graphics card draws graphics too fast, and the monitor refresh rate is too slow, some frames will be cached, and when the cache difference slows down After that, the data that continues to come in later will crowd out the previous data, which leads to the inconsistency between the current frame of the display and the next frame in the buffer area, and "screen tearing" occurs.
Let's talk about the impact of GOP on image quality. As mentioned earlier, GOP is the frame combination between one I frame and the next I frame, such as IBBPBBP... and so on. In a group of GOPs, because B and P Frames only record the difference, so the amount of data required is much less than I-frames.
Therefore, we can imagine that in the limited amount of data, if the length of the GOP is longer, the amount of data allocated to the I frame can be increased, and the quality of the I frame can be higher, and the I frame is the reference frame of the GOP, then The overall picture quality is also improved.
But isn't the longer the GOP, the better? The answer is of course no. According to what I said before, the P and B frames are generated with reference to the I frame, and there is a dependency relationship. The parsing time is much longer than the I frame. Setting too many B and P frames means that the parsing is not enough. It takes more time, and if there is a data problem with the I frame they refer to, then the data of this group of GOPs will all be wrong. It can be seen from this that the GOP is not as long as possible.
Audio and video synchronization
We all know that the player performs decoding and rendering separately when processing audio and video, so how can we achieve audio and video synchronization? We can think of our real world, how we understand the concept of synchronization, in fact, synchronization refers to simultaneous occurrence.
Then to achieve audio and video synchronization, that is to say, we need to add the concept of time stamp (PTS) to the audio and video. Audio frames and video frames with similar time are regarded as two synchronized frames. We can use this similar value. Call him the threshold. This threshold is not arbitrarily defined. He has an international standard called RFC-1359.
There are three general audio and video synchronization methods: video synchronization to audio, audio synchronization to video, and external clock for audio and video synchronization.
The method of synchronizing video to audio is usually adopted. This is because the video is played frame by frame, and the audio is played in a streaming form, that is, in a continuous and uninterrupted form. In terms of processing logic, it is more convenient to process the video played frame by frame. The algorithm of audio and video synchronization is shown in the following figure:
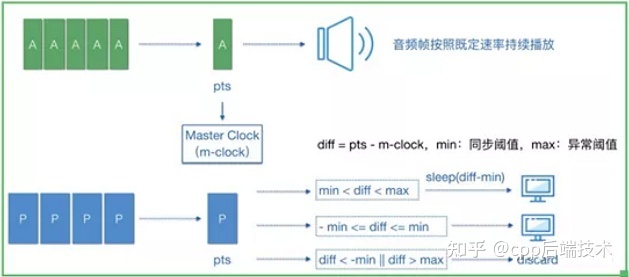
Audio and video synchronization algorithm
streaming protocol
Usually the volume of audio and video data is relatively large, so in the process of network transmission, there is continuous multimedia traffic. The technology of transmitting audio and video data in the network is called streaming media technology, and the protocol used for transmission is the streaming media protocol.
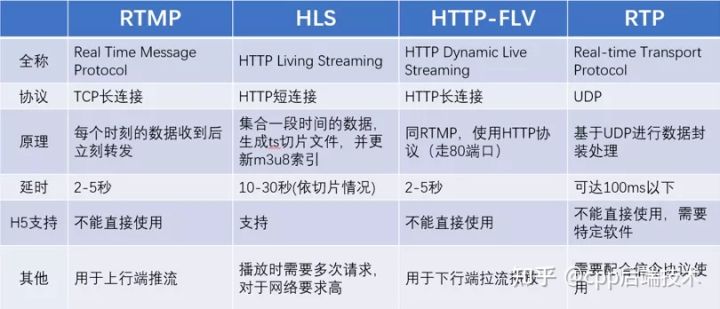
The commonly used streaming media protocols are as follows:
1. RTMP: Based on the seven-layer TCP protocol, it is cost-effective and is currently the standard protocol for live streaming;
2. HTTP-FLV: Based on TCP, using HTTP to transmit FLV streams, with strong distribution performance, suitable for CDN distribution;
3. HLS: Based on TCP, it is supported by the HTML5 writing standard, and the delay is large, but it is compatible with H5;
4. RTP: Based on the UDP four-layer protocol, the definition is simple and the performance is good, but additional signaling protocols are required.
In addition to the above four, some manufacturers will have their own protocols to achieve specific transmission purposes.
network jitter
First of all, let's familiarize yourself with several indicators that measure the quality of the network:
1. Packet loss rate: (data packets received by the local end/data packets sent by the opposite end) * 100%;
2. Delay: the receiving time of the peer end T1 - the time T0 of the data sent by the local end. Generally, RTT is used to evaluate the delay, that is, the round-trip delay, the time taken by the local end to send data, to the peer end to receive the data and confirm the reception;
3. Bandwidth: the amount of data that the network port allows to send and receive, in bps, sending rate: the amount of data actually sent and received, in bps. Bandwidth can be understood as the maximum sending rate;
Network jitter means that the data actually sent (received) is not sent (received). To judge whether it is jitter, it depends on whether the packet loss rate increases, whether the RTT increases, and whether the sending rate decreases.
JitterBuffer is generated to reduce the impact of network jitter on audio and video transmission. JitterBuffer is a buffer in the transmission process, connecting the decoder and the network protocol stack.
JitterBuffer will delay the audio and video transmission time for a while, cache the data in the buffer first, and also send the previously cached data to the receiving end. I understand it as the video cache when we watch TV online, so that If there is an occasional network jitter, it will not affect the user experience.
The benefits of JitterBuffer are:
1. Reduced the lag caused by slight network jitter;
2. Balance the data supply and demand of codecs and network protocol stacks;
3. Dynamically adjust the amount of data sent and received, and control the balance of data sending and receiving within a certain range.
Summarize
The above are the knowledge points written by LCF Xiaobian that integrates some other big guys' materials and some of their own understanding. The content covered by audio and video technology is actually quite extensive. I only list some basic concepts here. In the follow-up TRTC learning journey, if there is a chance, the editor of LCF Fa LED display will continue to discuss some other knowledge with you.









Shenzhen LCF Technology Co., Ltd.
Support Hotline
400-618-8884 / 0755-66833488(+86)187-0755-0669
Company Address
LCF Sound & Optoelectronics Industry Park, Gushu, Bao'an District, Shenzhen.
Copyright © 2004-2026 LCF LED Display Screen All rights reserved. Guangdong ICP 15089785-3 Subsidiaries: Dongguan Tongdachuang Industrial Co., Ltd., Anshun Lianshunda Technology Co., Ltd. (holdings)








")
